
-
数字资源——用户批量注册公众号,利用账号资源,引入优质内容,进行流量变现
-
优质产品——整合适合在微信生态销售的优质产品及源头厂家,通过私域进行营销
-
响啦平台——响啦数字共享平台利用AI创作优质内容,并进行内容分发
开启你的副业之旅
轻松赚取更多收入!
响啦,一个专注于数字共享经济的创新平台,致力于为想通过副业赚钱的人群提供简单、高效、可靠的赚钱机会


数字共享经济时代下的
——带货新模式

轻松三步,开启你的副业带货之旅
-

 注册公众号,加入响啦按照响啦的相关教程进行注册,轻松注册公众号,并授权加入响啦内容平台
注册公众号,加入响啦按照响啦的相关教程进行注册,轻松注册公众号,并授权加入响啦内容平台 -

 选择带货商品根据平台的推荐或自主选择商品进行带货,响啦则根据选品进行内容创作
选择带货商品根据平台的推荐或自主选择商品进行带货,响啦则根据选品进行内容创作 -

 定期扫码,坐等分佣用户需要对所有的公众号每3天分别扫码登陆一次,以保持账号的活跃度。内容引流产生了订单,每笔均享受分佣
定期扫码,坐等分佣用户需要对所有的公众号每3天分别扫码登陆一次,以保持账号的活跃度。内容引流产生了订单,每笔均享受分佣
简单操作,适合各类人群
-
 大学生快速上手,无需任何专业知识,轻松赚取零花钱
大学生快速上手,无需任何专业知识,轻松赚取零花钱 -
 失业人群打破束缚,帮你重新掌握经济主动权
失业人群打破束缚,帮你重新掌握经济主动权 -
 上班族利用闲暇时间赚取额外收入轻松掌控自己的副业
上班族利用闲暇时间赚取额外收入轻松掌控自己的副业 -
 带娃宝妈在家就能操作,不用担心时间和地点的限制
带娃宝妈在家就能操作,不用担心时间和地点的限制 -
 自由职业者更加灵活的工作方式,让你的收入再上新台阶
自由职业者更加灵活的工作方式,让你的收入再上新台阶
好的借力工具,才能轻松赚钱
-
 操作简单 省心省力
操作简单 省心省力简单操作,碎片化时间操作
无论你是谁,只要你有注册公众号的条件(一个人最多可注册25个公众号,加入平台仅需注册10个),就能开启副业之旅。无需专业技能,无需丰富经验,只要你有一颗想赚钱的心,响啦就为你敞开大门。
-
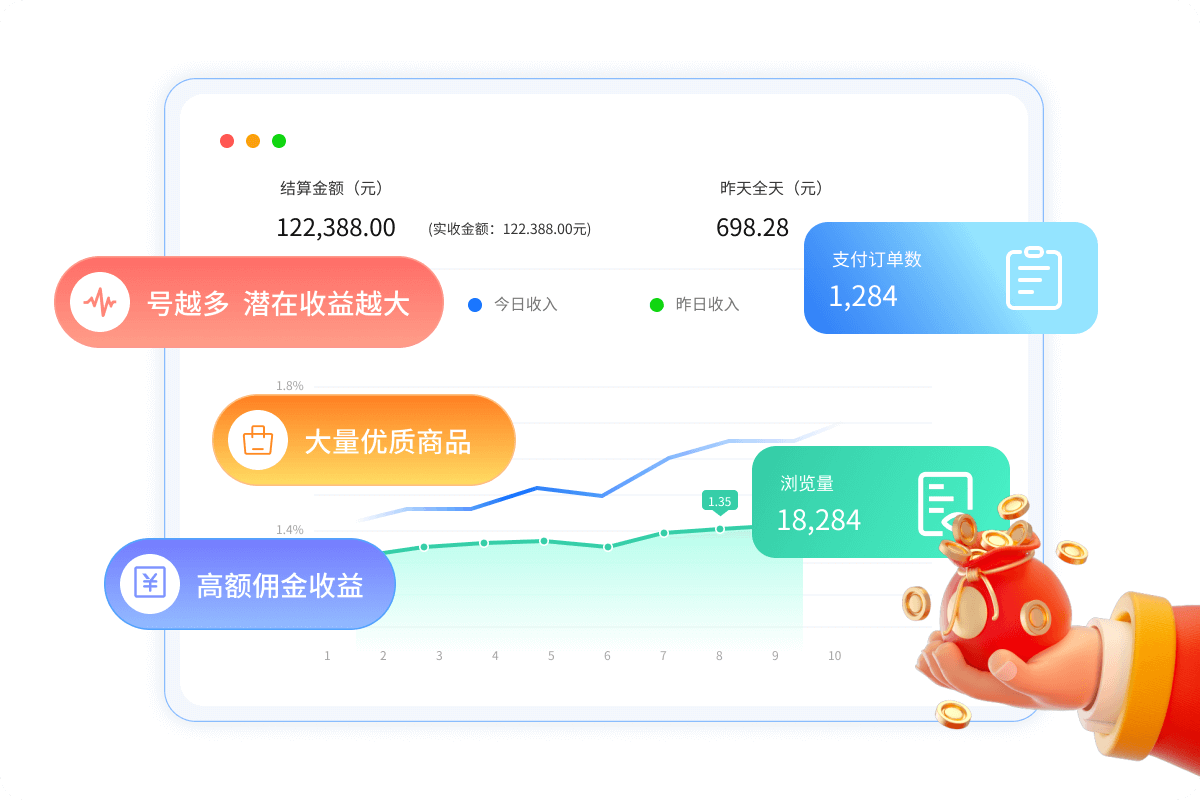 低门槛,高收益
低门槛,高收益丰厚的分佣,收益可观
你的公众号文章带货产生一单,你就能获得相应佣金。这意味着,你的每一个公众号都有可能成为你的赚钱渠道,注册的公众号越多,潜在的收益就越大。而且,平台上有大量优质的商品供你选择,满足不同用户的需求,让你的带货更容易成功。
-
 严格审核 优选商品
严格审核 优选商品高质量货源,任你挑选
平台的供货商都是经过严格审核的,这些产品质量有保障,价格有竞争力,能够吸引更多消费者购买,从而提高你的销售机会和收益。同时,供货商还会提供完善的售前和售后服务,让你无需为售后问题操心。
-
 零风险,放心加入
零风险,放心加入风险保障,让你无后顾之忧
您授权公众号的信息安全是我们最重视的事,平台仅通过微信官方API获取必要基础信息(OpenID、昵称、头像)。平台还特别推出贴心保障政策:使用系统满 90 天且满足基础运营要求,赚不到钱,可申请退款
我们深知你的顾虑,因此响啦平台特别推出贴心保障政策:
使用系统满 90 天且满足基础运营要求 ,若累计分佣为 0,全额退还会员费,让你无后顾之忧。若累计分佣小于会员费,退还差价,确保你的权益不受损。
告诉我们,还有什么可拒绝的理由呢?
一次正确的选择,拉开成长的差距
已帮助15328人获得副业收入
累计发放佣金¥2,876,000+
冯启彬
多媒体运营
我之前一直在摸索公众号怎么变现,后来发现了响啦平台,就开始尝试做公众号带货和问一问。刚开始我也没抱太大希望,结果今天一看后台,几个公众号的流量都起来了。最让我惊喜的是,今天看到还收到了7个订单的带货佣金,估计后面还有,挺开心的。对我来说,虽然刚起步,但已经比做流量主强太多了,至少收入能看见,而且过程也没那么累。现在信心越来越足了!
副业版会员
¥600.00
每月增收
10个
运营账号
郑婷雅
带娃宝妈
我是在朋友推荐下了解“响啦”系统的,刚开始也有点犹豫,担心被骗。后来我朋友跟我说他已经用这个系统赚到钱了,而且说不赚钱还可以退款,我才决定试试。现在刚加入不久,希望每个月多少能有点收入!
副业版会员
¥500.00
每月增收
10个
运营账号
吴彦琛
网站SEO
我现在用响啦系统差不多快两个月了,账号流量还可以,但变现个人觉得还是有点吃力。上个月收入1824,但还是觉得有点低了。其实我以前是做网站SEO的,但是现在不好做,就放着的。前几天我想换品类做虚拟资料类,觉得那种订单多,但平台说账号内容要垂直,不能乱换,不然容易被限流。也理解,毕竟平台现在规则越来越严了。我打算下个月再搞一批账号进来,争取达到月入3000块以上!
创收版会员
¥2200.00
每月增收
30个
运营账号
李世海
上班族
之前在网上看了很多副业教程,尝试过写公众号、投稿、做知乎,好像都挺难坚持,主要是太花时间。偶然的机会看到“响啦”这个平台,说是可以一键发文带货,我就也试试看。其实刚开始也没报太大希望,但它确实省事,文章不用我写,题材也都是现成的。这两个月陆陆续续赚了两千多,虽然不多,但够我多交个房贷了,还挺开心的,反正不累。
副业版会员
¥1256.00
每月增收
10个
运营账号
孙婉茹
在校大学生
我是一名在校大学生,平时课余时间很多,一直想找一份兼职赚钱。加入响啦平台后,我注册了10个公众号,按照平台的提示选品,每4天扫码登陆一次。没想到,第一个月就有了不错的分佣,现在每个月的分佣都能覆盖我的生活费用,减轻了家里的负担。感谢响啦平台,让我实现了经济独立!
副业版会员
¥950.00
每月增收
10个
运营账号
李琳颖
平面设计
我是学设计的,平时就爱搞点副业,像做图、剪视频啥的,但时间老是被占得死死的。今年三月,有朋友拉我进了一个叫“响啦”的平台,说是发文章就能带货赚钱。一开始我还不信,毕竟公众号这种老平台我以为早就没啥流量了。结果试了一下,系统直接给选题、排版我也不用操心,比我接设计稿划算太多了。这三个月我差不多躺着就赚了几千块,关键真省事,不用卷内容创意,我现在都想把它当主业了。
创收版会员
¥1800.00
每月增收
30个
运营账号
孙思达
图书馆行政
我是一个在图书馆做行政的女生,工作稳定但工资不高,平时喜欢写点东西,也想找点轻松的副业。朋友介绍我用“响啦”系统,说是可以通过发公众号文章带货挣钱。一开始我还以为很复杂,结果用下来特别简单,连选题和内容都不需要自己想,直接套用系统就行。几个月下来也赚了两三千块,虽然不是特别多,但比之前自己折腾半天写一篇没人看的文章要强很多了。现在就是每天坚持一下,当做种树,一点点慢慢长。
副业版会员
¥900.00
每月增收
10个
运营账号
周琎
残障人士
我是一名残障人士,没有正式的工作,一直想找个副业,增加一点收入。有一天我一个很好的朋友给我推荐了这个响啦平台,说注册一些公众号放进去,3天左右扫码登录一下就可以有收入。我半信半疑的用自己的微信注册5个公众号放进去。刚开始没有任何动静,我都准备放弃了,隔了一周多,我收到了第一单12元的佣金收入,让我很是意外。然后我又继续加了公众号进去,收入慢慢开始增加了,一个月下来我一共收到的佣金接近一千。
副业版会员
¥800.00
每月增收
10个
运营账号
常见问题
-
响啦平台是兼职平台吗?
响啦平台是副业平台,不是兼职平台。副业和兼职有本质的区别,副业更像创业,而兼职只是短期打工。副业可以通过长期积累实现复利效应,兼职则只能通过出卖时间和体力换取即时收入。副业的核心在于掌握生产资料,比如自己的账号、店铺或流量渠道,这些可以持续带来收入。兼职则没有复利效应,收入与付出的时间成正比。
在数字经济与共享经济深度融合的今天,"响啦"平台以创新模式打造了一个连接内容创作者、商品供应方与消费者的三方生态系统,为普通人开辟了一条"零技术门槛、低时间投入"的副业创收路径。平台通过整合微信公众号运营、AI内容生产与供应链资源,构建了"副业者-供货商-平台"三位一体的商业模式,帮助用户实现"轻资产创业"。
平台运营方为重庆龙旌网络科技有限公司,微信公众号内容带货模式与抖音带货,小红书带货一样。副业者注册多个公众号,由响啦平台帮助副业者创作内容,然后通过内容带货实现产品和服务的销售,副业者获得15%左右的佣金,无需副业者懂公众号运营和内容创作,只需将注册的公众号加入到响啦的内容创作系统中,由系统帮副业者进行内容创作。
同时,响啦平台做出承诺,如果足额加入的账号并按系统的基本要求进行必要的维护,90天收不回系统使用费,平台将退还差价(系统使用费-总分佣金额=退还差价)。退款可以直接在后台申请,符合条件会自动退款,无需人工审核。
-
响啦平台的商业模式是怎样的?
响啦平台的商业模式其实非常简单,副业者注册公众号加入到系统,无需懂得公众号的运营和内容创作,把运营和内容创作交给响啦平台。然后响啦平台整合了各类产品渠道,将优质产品放到响啦平台的小程序商城。这样的话,副业者创作的文章带货产生了销售收入,则享受产品的分佣(一般在15%左右),而平台因为提供了内容创作,则享受产品销售额的20%的服务手续费。而供货商提供产品的售前、售后、发货、换货处理,产品销售额除去平台的手续费和副业者的佣金外,全部归供货商所有。
通过这种三方共赢的方式,实现了各自的价值回报。销售数据透明,销售佣金实时可查看,产生的每笔订单立即在副业者的系统后台可以看到。佣金到账后,副业者也可随时提现到自己的账上。
-
响啦平台的系统使用费随时可退吗?
为保证用户的利益,切实做到不割韭菜,不收智商税。响啦平台做出承诺,若副业者使用系统90天后,分佣金额小于系统使用费,则平台将退还差价(系统使用费-总分佣金额=退还差价)。退款可以直接在后台申请,符合条件会自动退款,无需人工审核。
- 退款须满足如下条件:
-
1.加入足额的账号,如果是购买的10个账号的版本,则必须要加满10个公众号(订阅号或服务号不限)。如果是购买的30个账号的版本,则必须要加满30个公众号。
2.在加入的所有公众号账号中,至少有一个公众号完成了实名认证。如何实名认证公众号,可以点这里-点此查看内容 ,当然,这是指个人的实名认证,企业注册的公众号,实名可以在公众号的后台操作。
3.从足额加满系统版本要求的公众号数量起算,达到90天!记住:加满版本要求的账号数量起,才会开始计算时间,如果没有加满数量,则不会计算时间。
4.90天内每个公众号累计扫码次数达18次。现在响啦平台要求每三天需要进后台扫码登陆一次,增加账号的活跃度。每个月应扫10次,但是考虑到个别副业者的特殊情况,允许一个月漏扫4次。
5.90天后,累计分佣金额少于系统使用费。
-
公众号加入响啦平台后,选品需要注意什么吗?
将公众号授权添加到响啦平台后,需要进行选品操作,选品后平台才能根据你选择的商品进行内容创作,如果没有选品,则平台不会为你的公众号创作内容。
目前选品有两种方法:一种是系统推荐的产品,另外一种是自主选品。两种操作都是可以的,如果想省心,建议采用系统推荐的产品。
第一次选品后,后续相关产品有新增,系统也会自动为你更新新产品到后台。
-
一个人最多可以注册多少个公众号?
根据腾讯平台的最新规则,一个人最少可以注册25个个人公众号(一个人可以注册并实名5个微信号,而每个实名的微信号可以注册5个公众号,这样算下来,一个人最少就可以注册25个公众号),注册公众号还有一个办法,就是注册个体工商户,现在在淘宝找注册个体工商户的人,有些省份注册个体工商户仅需要50元左右,注册个体工商户全部是线上操作,不需要到线下去签字什么的,而且不需要代账(自己在手机上每个季度操作一次申报就行)。
需要注意的是,一个手机号只能注册1个公众号,所以需要准备最少10个能接受验证码的手机号。一方面可以通过亲戚朋友帮收验证码,另外一方面可以在淘宝、拼多多找接码平台,接收验证码(一般3-5元一个验证码),亦可联系QQ:3179537872 代为寻找接码渠道
如果仍没有搞明白,可以看我们的教程:一个人注册25个公众号的详细步骤
-
公众号怎么进行实名认证?
公众号的认证有两种,一种是个人实名认证,个人实名认证是免费的。一种是企业实名认证。企业实名认证是要收费的,需要交300元认证费用。建议采用个人实名认证。
详细认证过程请查看相关教程
-
添加到响啦平台的公众号可以删除或替换吗?
目前响啦平台的副业者,可以对运营的公众号进行删除操作,但删除之后,应及时补足系统版本的账号数量。否则会影响到退款。
-
如何监控我的公众号发布的内容呢?
登陆响啦平台的用户后台,点击左侧的“文章管理”,即可查看系统为公众号创作的文章内容。
-
成为响啦平台的团长,有什么好处?
团长制的设计,是响啦平台的最大亮点。目前申请成为团长需要缴纳1000元服务费,平台设计的初衷是用户可以免费申请成为团长,但为了怕团长浪费平台资源所以才设置的一个门槛。因为,如果团长真正有人脉资源,能组建一个小型营销团队,这个费用平台是可以全额返还的(团长每发展一名团队成员,平台返现50元给团长,直到返完为止。)
简单给大家讲一下成为团长有什么好处。
团长制是为有一定人脉资源的人设计的,比如群主、社团、企业、厂长、学生会等。成为团长就相当于成为了一个部落首领,成为团长后,就可以成为供货商,如果团长自己拥有自主品牌的商品或拥有产品的渠道,就可以在供货商后台上传自己的产品,并设置佣金。团长发展的所有成员均会默认为团长的产品带货,实现销售后,团队成员则享受产品的分佣。团长则实现了产品的大量销售,每一个团队成员犹如团长组建的小型销售团队,而团队的每一个成员均成为团长不发工资的营销成员。
如果团长没有自己的产品也没有产品的渠道,也可以从1688货源平台去筛选适合在公众号上销售的产品(需要结合公众号人群画像和微信指数来确定产品),如果不知道如何选择商品,也可以咨询平台客服,平台可提供专业的免费培训。
响啦 "团长"招募计划 —零风险创业
团长高级会员计划,专为品牌主、创业者及人脉资源丰富者打造!
成为“团长”,即可在平台上架自有商品,并发展团员,所有团队成员均带货团长的产品,实现裂变式增长,轻松扩大销售渠道。

